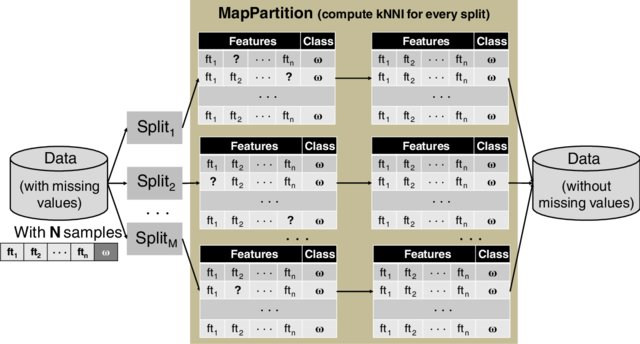
 The k-nearest neighbors algorithm is characterized as a simple yet effective data mining technique. The main drawback of this technique appears when massive amounts of data, likely to contain noise and imperfections —are involved, turning this algorithm into an imprecise and especially inefficient technique. These disadvantages have been subject of research for many years, and among others approaches, data preprocessing techniques such as instance reduction or missing values imputation have targeted these weaknesses. As a result, these issues have turned out as strengths and the k‐nearest neighbors rule has become a core algorithm to identify and correct imperfect data, removing noisy and redundant samples, or imputing missing values, transforming Big Data into Smart Data, which is data of sufficient quality to expect a good outcome from any data mining algorithm.
The k-nearest neighbors algorithm is characterized as a simple yet effective data mining technique. The main drawback of this technique appears when massive amounts of data, likely to contain noise and imperfections —are involved, turning this algorithm into an imprecise and especially inefficient technique. These disadvantages have been subject of research for many years, and among others approaches, data preprocessing techniques such as instance reduction or missing values imputation have targeted these weaknesses. As a result, these issues have turned out as strengths and the k‐nearest neighbors rule has become a core algorithm to identify and correct imperfect data, removing noisy and redundant samples, or imputing missing values, transforming Big Data into Smart Data, which is data of sufficient quality to expect a good outcome from any data mining algorithm.
Read more.
Authors: Isaac Triguero (University of Nottingham), Diego García-Gil (University of Granada), Jesús Maillo, Julián Luengo (University of Granada), Salvador García (Universidad de Jaén), Francisco Herrera (University of Granada)
Transforming big data into smart data